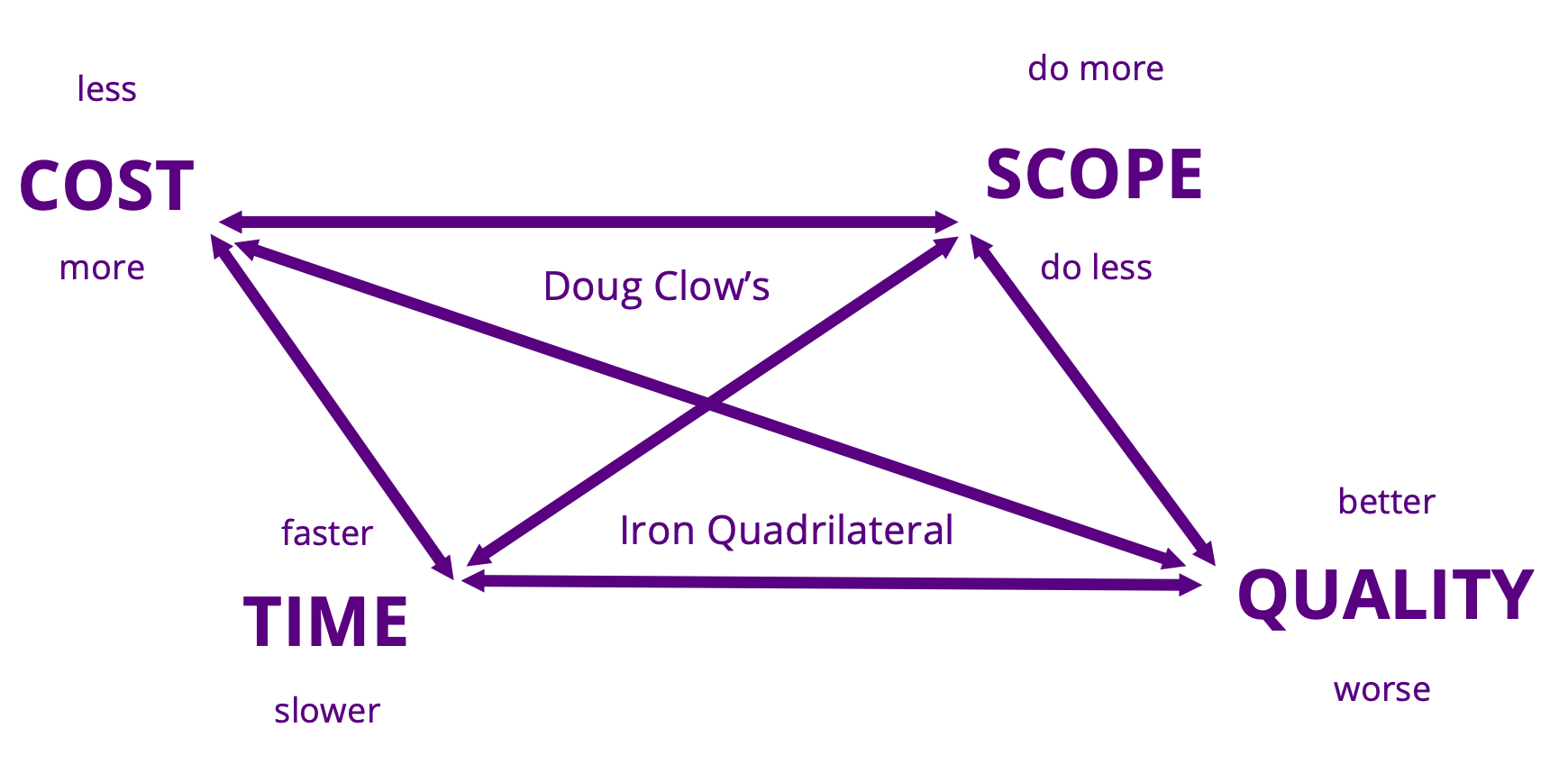
You may well be familiar with the Iron Triangle of project delivery: time, quality, and cost are closely interlinked and trade off against each other. Any improvement on one of those aspects will put downward pressure on the other two.
“Faster, better, cheaper: you can only pick two” is the pithy version.
And that’s if it’s done well. You can be slow, worse, and expensive.
I like to break it down further to an Iron Quadrilateral of time, quality, scope, and cost. Quality and scope can trade off directly: do less but better, or more but worse. And they both trade off against the others.
Here, for the first time, is a quick sketch of it!
The UK Government’s aim to have a big push on booster vaccinations is really great. But their target to “offer a booster to everyone eligible by the end of January” is a terrible target. It misses out the vital importance of takeup, is an obvious setup for fiddling the target, and fundamentally fails to address what we actually care about. With luck it won’t matter, because of the clear sense of mission.
These are some of the principles I’ve drawn from more than 20 years experience in what we now call data science: using data to understand and improve human systems. They’re more guidelines than rules, particularly the ones rating one thing above another.
I have two lists: this one for project leaders and managers, and that one for project sponsors. This one is focused on issues around how you deliver a project and what sort of a project it is; the project sponsor one is more about how you frame and resource a project. Obviously, they overlap and have great synergy.
These are some of the principles I’ve drawn from more than 20 years experience in what we now call data science: using data to understand and improve human systems. They’re more guidelines than rules, particularly the ones rating one thing above another.
I’ve split this in to two lists. This one is aimed towards project sponsors, but obviously it’d be useful for anyone who has to interact with project sponsors. I have another one for project leaders. The idea is that this one has more of the things you need to bear in mind in setting up and resourcing a project and connecting it to the rest of the organisation, and the other has more of the things you need to bear in mind in getting the project done.
I can’t get this news story about sweary parrots out of my head. Lincolnshire Wildlife Park has had to separate five African Grey parrots after they started swearing too much, egging each other on to tell people to F off and then laughing.
I think these profanity-spouting birds illustrate a process that we see more widely, to lesser degree in traditional media and to a great degree in social media. (It’s also closely related to some recent steps forward in AI, but I’ll leave that mostly aside in this post.)
Many parrots are good mimics, and African Greys are particularly good at it. And they have a widely-known tendency to get potty-mouthed and say completely outrageous things.
How come? Why would a bird do that? They are highly intelligent, for birds, but it really isn’t that they want to insult people and say awful stuff because they’re deep down horrible. We say people are “parroting” something to mean they don’t understand it and are merely mimicking the noise, and we can be pretty sure that’s the case for our actual parrots here.
I think this sophisticated awful behaviour – or perhaps more precisely, this awful behaviour that appears sophisticated – is the result of the interaction between two components: a generative one, and a selective one. (If you know about AI you’ll see where my mind is going.) The generative component is the parrot’s ability to mimic what it hears. The selective component is the parrot’s ability to pick up on social cues and choose things to mimic that reliably get a reaction and attention from people.
Having a parrot pipe up unexpectedly and drop an F bomb will, indeed, reliably get a reaction and attention from people. So our smart-enough parrot tries mimicking things it hears, and when it gets a reaction, mimics that thing more often in future. And that often means persistent cussing.
This type of feedback loop is immensely powerful. We can see it in lots of places. Toddlers do it. Teenagers do it. And adults do it in the media.
Do we see this in traditional media? Oh yes. We have as the generative process the efforts of a whole creative media industry, and the selective process is complex and multi-layered, but what gets a reaction and attention is a large part of it. Media organisations are desperately concerned with audience. Some of what draws an audience is good, but terrible things can also be a substantial draw.
‘News values’ – what the news prioritises and highlights – have been identified as potentially problematic since the 1950s. “If it bleeds, it leads” is a very old slogan. Reading the local weekly newspaper can be a bit depressing, until we remember that this is a curated list of the most shocking, lurid, and outrageous things that have happened with any tenuous connection to our area over the last seven whole days, which gives some reassuring perspective.
It’s not just news, of course. ‘Reality’ television is clearly well down this path of being rewarded for shocking behaviour.
What about social media?
Here the generative process is a much broader pool of humans composing (mostly) short bits of media, and the selective process is what generates ‘engagement’. Media platforms are optimised to bring more of what generates engagement to users, because that keeps them on the site longer and generates more possibilities for selling adverts. Users learn the sort of thing that tends to be rewarded by the platform, and off it goes in that powerful feedback spiral.
As before, sometimes good things generate engagement, but terrible things are often more reliable in prompting a reaction.
We see this in our everyday lives online. Occasionally you get lovely, uncontroversial things where somebody has done something exceptionally creditable or particularly cute. But more often you get conflict, hostility, and outrage. And some extremely dark stuff can be amplified by the process.
Mr Zuckerberg has sometimes defended Facebook as merely holding up a mirror to humanity. It’s not a mirror, it’s a feedback process that is vastly more powerful. A nuclear chain reaction is perhaps a better analogy. It is possible to harness that power for good, but it’s extremely challenging in engineering terms, and it’s much simpler just to use it to blow stuff up, particularly if it’s someone else’s job to clean up the radioactive mess left behind.
Let’s get back to our parrots. One occasionally-sweary bird isn’t so much of a big deal. The problem at the wildlife park started when they housed these particular five parrots together. One would swear and another would laugh, and with the mimic-reaction feedback, they were soon all swearing like troopers. The BBC report that the park’s chief executive, Steve Nichols, said, “if they teach the others bad language and I end up with 250 swearing birds, I don’t know what we’ll do”.
With social media, we have the human equivalent.
This isn’t a new phenomenon, and it’s not a new observation to highlight the issues with the attention economy. But next time I see something terrible getting a lot of attention on social media, I’m going to think of a bunch of sweary parrots.
All the very best to all involved in UK universities as we hit last-minute decision time for the new term/semester. As of 1.18am today, Thursday 10 September 2020, we now have as much guidance as we’re going to get.
This is the blog post version of a long thread I posted on Twitter earlier today. In short, I advise going all-online now, but all the best anyway – you’re great.
Go all-online now, but all the best anyway – you’re great.
First, I want to apologise that some of my commentary has made it seem to some that I don’t appreciate or understand the scale of the work being done, and that I’m unsympathetic to staff working on plans that differ from what I’m arguing should happen. That’s not the case. I’ve also inadvertently contributed to a sense that those working on opening physical spaces don’t care about students. That’s simply not true. People who disagree with me on this are driven by a deep concern for students. And they’re working bloody hard on good stuff.So although I may disagree on some tactics, I want to strongly support and applaud the enormous efforts going on across the sector. These decisions are not easy, and much hard work is being done by people who don’t get much say but do get much stick, and that’s unfair.
This latest guidance is obviously not the last oddly-timed intervention from the Government we’ll get, so all those systems for rapidly appraising and acting on new developments will need to be on hot standby for the foreseeable future. The Government guidance sets out ‘tiers of restriction’ in response to local outbreaks. Most universities already have a range of scenarios mapped out. One of today’s urgent jobs will probably be to map those onto these new official response ‘tiers of restriction’.
My view remains that it would be better to choose now to teach online, except for those things that can only be done in person – i.e. starting at Tier 2 or 3, not Tier 1 (default position).
Despite what some say, that is not an easy decision. It’s a difficult balance. My two main reasons for deciding now to teach online are to reduce the spread of the virus, and to reduce the workload (and cognitive load) of staff and students in keeping multiple scenarios live – which will make the online learning better.
But this is not an easy option. Not least because the Government explicitly expects most universities to open their physical campuses, even now. And students will, quite reasonably, be furious to be moving all that way and taking out accommodation contracts etc if it’s all online anyway at late notice. For most courses in most subjects in most universities in most subjects, teaching online now will not be as effective and engaging a learning experience as teaching in person. I’m ex-OU. I am utterly convinced you can do world-class university education online. But the Open University has had decades to prepare and has a completely different organisational setup and staff base. Staff across universities have worked enormously hard since the start of all this to move everything online, and the transformation in capability is truly astonishing. But realistically – with some very notable exceptions – most online provision will not be as good as in person. Yet! Although it’s important to note that Covid-secure measures mean in-person teaching is very constrained, and less good than it would’ve been in normal times.
You’re darned if you do, but damned if you don’t.
So why on earth do I still say start with a more restrictive, online approach to university teaching? Two main reasons:
take more responsibility to reduce the spread of a pandemic virus than the Government is requiring, and
reduce the pressure on staff.
(1) Whether or not to take a stronger line on risk reduction than the Govt advises isn’t easy, and reasonable people can come to different views. I would give greater weight to advice from the Govt if it had been more effective in dealing with the pandemic to date. I’d also give it more weight if the advice on reopening buildings and campuses had more explicit acknowledgement of the risk to staff and the community. Universities are more than their students, and have responsibilities to their host communities.
There’s a maxim from public health on taking early, effective action: you’re darned if you do, but damned if you don’t. Effective action is unpopular & will inevitably look like too much too soon: there is no major disease! If it works, it’ll appear unnecessary in hindsight. But failing to act to prevent wholly foreseeable disasters is not just unpopular, it’s massively condemned. Especially when there are avoidable deaths. SAGE says, in their report on managing transmission of the virus in universities, “Outbreaks in HE are very likely.” Physical opening is socially acceptable now, but may not be in retrospect.
(2) Going all/mostly-online now means staff can largely forget about the physical teaching scenarios and focus on the one or two that will have to be delivered. That saves effort and reduces uncertainty and worry. All of which would be hugely welcome. Running multiple possible scenarios comes at enormous cost. Everyone involved has to make multiple plans. There isn’t enough time to do everything properly, so that means the plans for each scenario are less good than if there were fewer to deal with – preferably just one.
There’s also the cost of switching from one scenario to another, in direct staff and student time in implementing the new arrangements, and also in cognitive load in rethinking how your routines work. Starting more restrictively means fewer scenario switches.
You absolutely can get better at teaching online. I would bet that teaching will more rapidly improve if staff are doing it than if they’re struggling along with massively complex hybrid arrangements they can barely cope with. Doing both simultaneously is really hard.
I want to salute and acknowledge the enormous, spectacular efforts being made across higher education.
But! I can see how others can come to a different view, and I may be wrong about how likely outbreaks are (I do hope so), and your university might well turn out to be one of the lucky ones despite – as Mr Gove infamously remarked – choosing to run things quite hot. And providing some in-person teaching will, at the moment, in many instances, result in a better experience for students. If you do have in-person time, do prioritise group-forming and community-building activities over curriculum delivery. You can build community online, but it’s much harder. You can teach more effectively online when there are good relationships between your learners already. Make good use of the limited time you may have. @ProfSallyBrown has some excellent ideas in this line in her post on Wonkhe.
Regardless of any difference of opinion about tactics, I want to salute and acknowledge the enormous, spectacular efforts being made across higher education. Academic staff, professional staff, and non-professional staff have all worked fantastically hard and worked wonders. Students and students unions have also done extraordinary things, and engaging with them is the best antidote to gloom about the current situation and the future. Even when they present with a diversity of strongly-held views. Perhaps particularly then!
Finally, keep an eye to the future: it’s hard to make headroom for long-range plans, but this won’t last forever. I’m sure that universities who make continuing good use of the expertise in online working developed in these hard times will thrive in the more distant future.
I’m really excited to launch a new and unique service: tutxoring!
For most things you need to learn, there are many experts on the subject from whom you can learn, and a vast range of learning materials: courses, textbooks, videos, communities. For most topics, there’s an agreed curriculum, a set of things that most experts agree you need to know. But for the most difficult, the most challenging, and the most ground-breaking learning, there’s almost nothing to help you. That’s where tutxoring comes in.
The model comes from the later stages of PhD supervision, or some forms of an Oxbridge tutorial. While the supervisor or tutor usually starts with a better understanding than the student, good students will, by the end, be among the world experts in the specific area they’re working in, and the role of the supervisor or tutor becomes much more of a guide than a direct teacher.
This is just to whet your appetite: there are more details about what tutxoring is on my website, as well as an even longer discussion about tutxoring, how it works, and how I’m well placed to offer it.
Many thanks to everyone who provided early feedback on a sneak preview. You’ll see I’ve changed the name based on what you said. And a particular salute to the old guard who still have my blog in their RSS feed reader.
If you’re interested in tutxoring, want to find out more, or want to discuss how tutxoring can help you, do please get in touch.
We need to seriously consider doing a lot less with student data right now. Stopping data logging will reduce the impact on our systems and, more importantly, on our students.
As a longstanding learning analytics researcher, I don’t say this lightly.
“Waiting for Moodle to render this page is taking longer than it takes to get to the lecture theatre on the other side of campus.”
The Covid-19 coronavirus crisis is profoundly changing society, including universities. There’s been a mad dash to online teaching, and a mad dash to online assessment close behind. Those of us who’ve been enthusiasts for online learning for a long time know that this may be a huge success in some places, but that it isn’t going to go terribly well in many others. It’s easy for our eyes to light up at the thought of all that interesting data that all that online activity could generate.
But hold up. In a crisis, we need to prioritise what’s most important. Frankly, the benefit to students of most of our data gathering is not sufficient to justify it getting priority in a crisis. And our evidence of what benefit there is has improved since I wrote a rather despairing paper with Rebecca Ferguson about it, but not hugely. I do believe it’s worth pursuing. But it absolutely can wait, so it should wait.
A big turn-off
What if we just turn all that data logging off for the duration of the crisis?
We’d reduce the impact on our systems. Online learning systems are under massive strain as IT staff and suppliers struggle valiantly to deal with a completely unprecedented spike in demand. With a well-designed and well-tuned system, data logging needn’t be a huge drain on front-facing server resources. But when you’re rushing to scale up, you don’t have the time to tune it well and built a robust and separate data architecture. It will make the IT people’s life much easier if we just drop those requirements for now. It would, at least, be one less thing for them to worry about. And it might well materially improve performance, particularly on hastily-deployed systems where there hasn’t been time to optimise them.
We’d also reduce the impact on our students. Most academics are only in the student data business to make things better for students – but there are other interests at play too. Students are quite reasonably concerned about how their data is being used at the best of times. There isn’t the time to do all the engagement around data privacy that good practice requires, and that you need to properly address understandable and quite reasonable concerns. We could just steamroller them in to it. This seems to be happening a lot, and there’s even been some commentary from UK ministers about the GDPR that might be useful political cover for it. Or we could just … not do that, and give them a break. Deal with their worries about data privacy by sharply reducing the amount of data we collect. I think, given all that this cohort is putting up with, and is going to have to put up with in the near future, they badly need any break we can give them.
What can’t wait?
There will be some exceptions. Obviously, where you have a cognitive tutor setup, it would be nonsense to turn off the logging – and, not coincidentally, that’s where we have the best evidence of direct student benefit.
More widely, I’d argue for saving the last login information for each student so their tutor can see who’s been able to access the system and who hasn’t. I can’t instantly think of good papers showing this, but my strong hunch from practical experience with predictive modelling is that a huge chunk of the benefit that can come from such systems is increasing awareness among tutors of which of their students hasn’t been able to study for a while. We can do that directly with a lot less impact on students and servers.
And obviously, some data has to be recorded to operate an online learning system at all.
More later
For the avoidance of doubt, I am not for one minute arguing that learning analytics should close down and give up. I do still believe that there is huge potential from using students’ data to improve their learning, and that there’s more to be gained in future than has been done so far. I am arguing that we should be humble about what we can offer and prioritise the benefit to students. That is, after all, the whole point of learning analytics.
Learning analytics researchers and practitioners have never been in more demand in their organisations. We understand the practicalities of online learning in ways our more traditional colleagues don’t. It’s not like we’d be short of stuff to do if we spend the next months prioritising support for them and for student than our data-gathering projects.
We should do a lot more with student learning data … and we should do it later, when all this is over.
For those of you who follow my blog, following up on my post about Covid-19 and data, this is a quick note to say I’m doing some work on Covid-19 (coronavirus SARS-CoV-2). I’m curating a list of authoritative sources, and on Twitter, and I’m offering consultancy and workshops on organisational preparedness, along the lines of this workshop outline.
NB I do have some health and medical background but I am a data and learning professional, not a clinician, epidemiologist, or public health person.
“The virus is called COVID-19. No R. Call it CORVID one more time and I’ll peck your eyes out.”
Data science, BI and in fact any statistics all start with simple counting. That first bit is surprisingly hard, and getting it right is often most of the work. The current COVID-19 coronavirus outbreak shows this up nicely.
You can make as sophisticated a model as you like for an outbreak, to estimate things like the basic reproduction ratio (R_0, how many new cases each case is expected to cause, on average, which tells you how far it’s spreading), or the case fatality rate (how many people who catch it die of it), or the likely extent of the outbreak (how many people might catch it), and all sorts of stuff about how fast this is all happening or likely to happen.
But all that crucially depends on simple counting: how many have it at a given point, how many have died, etc. With the latest figures, we see how hard that is. The number of new cases in China jumped from 2,000 on Weds to 15,500 Thurs – because counting methodology was changed.
The numbers have changed retrospectively, too – I copied those numbers down yesterday, but today it looks like it was a 400 increase on Weds and a 15,100 on Thurs. This would be hard to get right even if there wasn’t a massive health crisis there.
Counting infections is always tricky, but surely deaths are easier? Turns out there are surprisingly difficult edge cases at the edge of life, but those don’t come up often, and almost everyone agrees about most deaths.
But even then, you’re probably getting data from multiple sources and combining them and that can lead to problems. Like today’s news that 108 deaths have been removed from the figures because they were double-counted.
It’s easy as a data scientist to say we need to invest in better data, and sometimes that’s right. But getting good basic counting data is hard, and expensive, and cannot be the absolute priority. The data you’re dealing with will always be messy to some degree.
Speaking of degrees, this crops up in education and learning. ‘How many learners do we have right now?’ is the basic question that is the denominator for pretty much any learning or teaching metric you care about.
And that is surprisingly hard to answer sometimes. There are late registrations, retrospective registrations, de-registrations, retrospective de-registrations, provisional versions of all those, and that’s just dealing with individuals.
When you have organisations buying in learning, it gets even worse: how many are provisionally ordered, how many are finally ordered, how many are catered for, how many show up, and how many are invoiced for are all different, and not the same as how many learned anything.
Speaking of invoices, cash at least should be easy to count? It should be clear when a customer paid us, right? Oh, my sweet summer child. That sound you hear is the entire accounting profession sniggering.
Suffice to say that the same payment can legitimately have different dates for cashflow, annual accounting, VAT, other taxes, and who knows what other purposes. Organisations are incentivised to manipulate this data, and most organisations respond to incentives.
Summarising a wide ramble: Even the simplest of data, like ‘How many people have COVID-19?’ can be surprisingly hard to get authoritatively. Getting better data is rarely a business imperative. Be cautious about interpreting your advanced statistical models.
Also, be kind to people who are working hard to do really difficult jobs in really difficult circumstances. And don’t make it harder by spreading misinformation.
Check with authoritative sources before passing on information. It does not help to spread stuff you think might be dodgy or far-fetched ‘just in case’. Most people who pass on misinformation don’t mean to cause problems. Check it’s right first. You can help protect your friends and colleagues from this hazard.
For hard research info, there’s stuff on the WHO site (currently under ‘technical information’ and ‘global research’) https://www.who.int/emergencies/diseases/novel-coronavirus-2019 and many publishers have made research freely available, and some have free-access portals on the topic, e.g.
This data is pretty good, but don’t treat it – or any data! – as representing the objective truth.
—
This work by Doug Clow is copyright but licenced under a Creative Commons BY Licence.
No further permission is needed to reuse or remix it (with attribution), but it’s nice to be notified if you do use it.